JVM
基础概念
功能
- 解释与运行:对字节码文件中的指令,实时解释成机器码,让计算机执行
- 内存管理:自动为对象,方法等分配内存,自动的垃圾回收机制
- 即时编译:对热点代码进行优化,将热点代码的机器码存放到内存中(JIT)
JDK vs JRE vs JVM
- JRE:Java 运行时环境和必要的类库
- JDK:包含 JRE 及 javac(编译器),jdb(调试器)
- JVM:运行字节码的虚拟机
JVM 组成
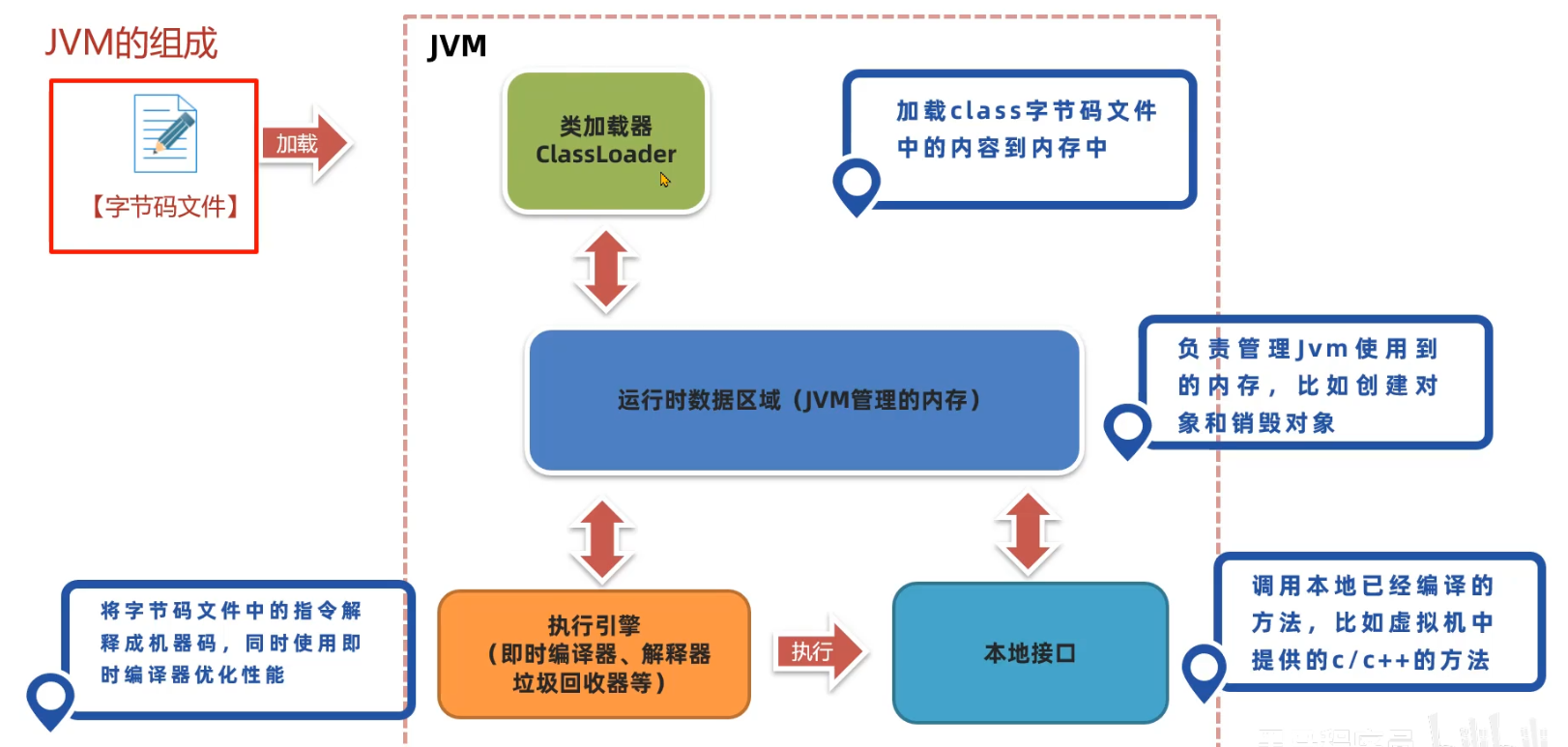
字节码文件
组成
- 基本信息:魔数、字节码文件对应的 Java 版本号,访问标识(public final 等),父类和接口
- 常量池:保存了字符串常量,类或接口名、字段名,主要在字节码指令中使用
- 字段:当前类或接口声明的字段信息
- 方法:当前类或接口声明的方法信息,字节码指令
- 属性:类的属性,如源码的文件名,内部类的列表等
通过文件的头几个字节去校验文件的类型,如 Java 字节码文件的文件头为 CAFEBABE,称为 magic 魔数
工具
javap:javap -v 字节码文件路径 > 输出路径 (jar -xvf 解压 jar 包)
jclasslib 插件
阿里 arthas:https://arthas.aliyun.com/
- dump -d 目标路径 字节码路径:查看字节码文件
- jad 文件路径:反编译源代码
类的生命周期
加载 -> 连接 (验证 -> 准备 -> 解析) -> 初始化 -> 使用 -> 卸载
加载阶段
- 类加载器根据类的全限类名通过不同的渠道以二进制的方式 加载字节码信息
- 加载完后,JVM 将字节码中的信息保存在 内存的方法区 中,生成一个 InstanceKlass 对象,保存 字节码文件的所有信息,包含实现特定功能的信息如多态的信息(c++语言)
- JVM 还会在 堆中 生成一份与方法区中的数据类似的 java.lang.Class 对象,作用是在 Java 代码中去获取类的信息(反射)以及存储静态字段的数据(JDK8 及以后),字段/方法(静态字段)
推荐使用 JDK 自带的 hsdb 工具查看 Java 虚拟机内存信息。
工具位于 JDK 安装目录下 lib 文件夹中的 sa-jdijar 中。启动命令:java -cp sa-jdi.jar sun.jvm.hotspot.HSDB
jps 查看运行进程 pid
连接阶段
- 验证:检测 Java 字节码文件的 规范约束
- 准备:为静态变量(static)分配内存并设置初始值,final 会直接赋值
- 解析:将常量池中的符号应用替换为 直接引用(内存地址)
初始化阶段
- 执行静态代码块中的代码,并为静态变量赋值
- 执行字节码文件中 clinit 部分的字节码指令(按 java 编写顺序一致)
导致类的初始化:
- 访问一个类的 静态变量或静态方法,注意变量是 final 修饰并且等号 右边是常量 不会触发初始化,在准备阶段初始化
- 调用 Class.forName(String className)
- new 一个该类的对象
- 执行 Main 方法的当前类
-XX:+TraceClassLoading 参数可以打印出加载并初始化的类
注意:
- 直接访问父类的静态变量,触发父类的初始化,不会触发子类的初始化
- 子类的初始化调用之前,会 先初始化父类
- 数组的创建不会导致数组中元素的类进行初始化
- final 修饰的变量如果赋值的内容需要执行指令才能得出结果,会在初始化阶段进行初始化,而不是在准备阶段,如
Integer.valueOf(1)
类加载器
类加载器的分类
虚拟机底层实现(C++ Hotspot):加载程序运行时的基础类,如 java.lang.String,启动类加载器 BootStrap
扩展类加载器(Java):继承自抽象类 ClassLoader,扩展类加载器 Extension,应用程序类加载器 Application
BootStrapClassLoader:加载 /jre/lib 下的文件,使用
-Xbootclasspath/a:jar包目录/jar包名ExtClassLoader:加载 /jre/lib/ext 下的文件,使用
-Djava.ext.dirs=jar包目录(; 分隔)AppClasssloader:加载 classpath 下的类文件
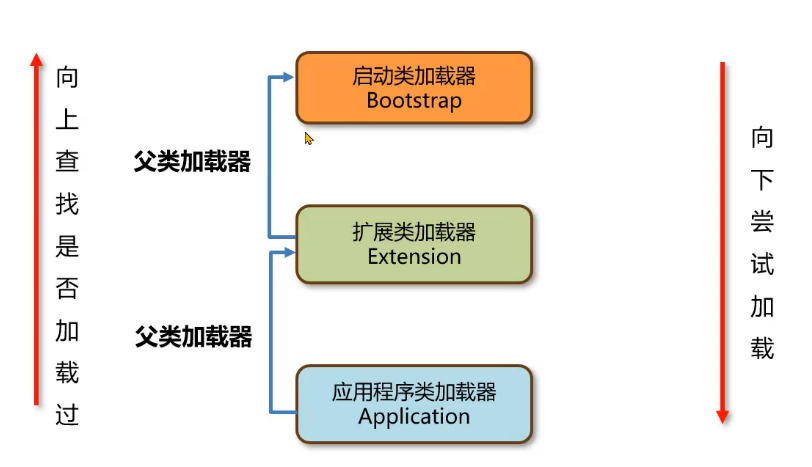
双亲委派机制
当一个类加载器接收到加载类的任务时,会 自底向上查找是否加载过,再自顶向下进行加载
使用指定类加载器加载:
ClassLoader classLoader = Demo2.class.getClassLoader();
Class<?> stringClazz = classLoader.loadClass("java.lang.String");
当一个类加载器去加载某个类的时候,会自底向上查找是否加载过,如果加载过就直接返回,如果一直到最顶层的类加载器都没有加载,再由顶向下进行加载。
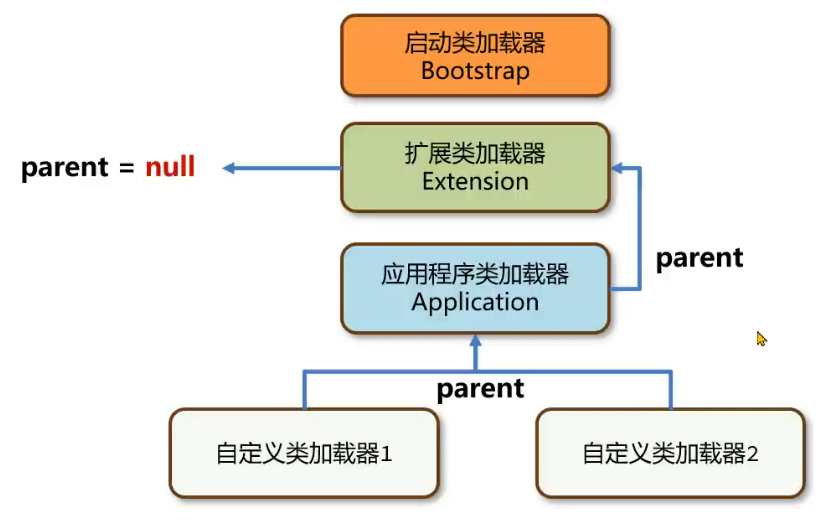
应用程序类加载器的父类加载器是扩展类加载器,扩展类加载器的父类加载器是启动类加载器。
双亲委派机制的好处有两点:第一是避免恶意代码替换 JDK 中的核心类库,比如 java.lang.String,确保核心类库的完整性和安全性。第二是避免一个类重复地被加载。
打破双亲委派机制
自定义类加载器:Tomcat
重写 loadClass 方法,将双亲委派机制的代码去除
线程上下文类加载器(AppClassLoader):JDBC
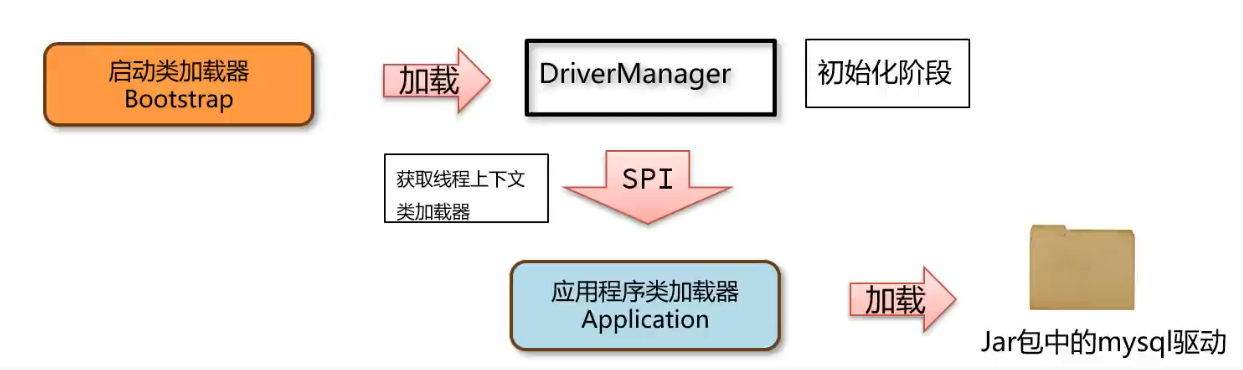
ClassLoader c1 = Thread.currentThread().getContextClassLoader(); //获取
Thread.currentThread().setContextClassLoader(classLoader); // 设置运行时数据区
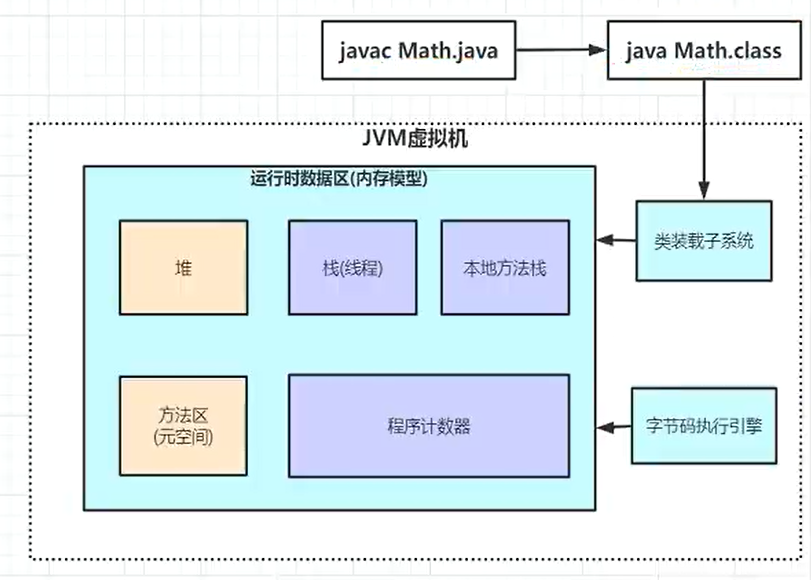
程序计数器
PC 寄存器,记录下一条指令的地址,线程不共享,保证线程切换时能回到之前的位置
Java 虚拟机栈
每个方法调用使用栈帧保存,随着线程创建而创建,销毁而销毁
栈帧
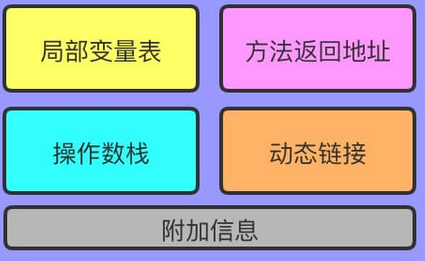
- 局部变量表:对象 this,方法参数,局部变量
- 操作数栈:存放执行指令过程中需要的临时数据
- 动态链接:指向运行时常量池的方法引用
- 方法返回地址:方法正常退出或异常退出的地址
栈内存溢出
- 栈帧过多,导致 StackOverflow 错误
- -Xss 栈大小(默认 1M)
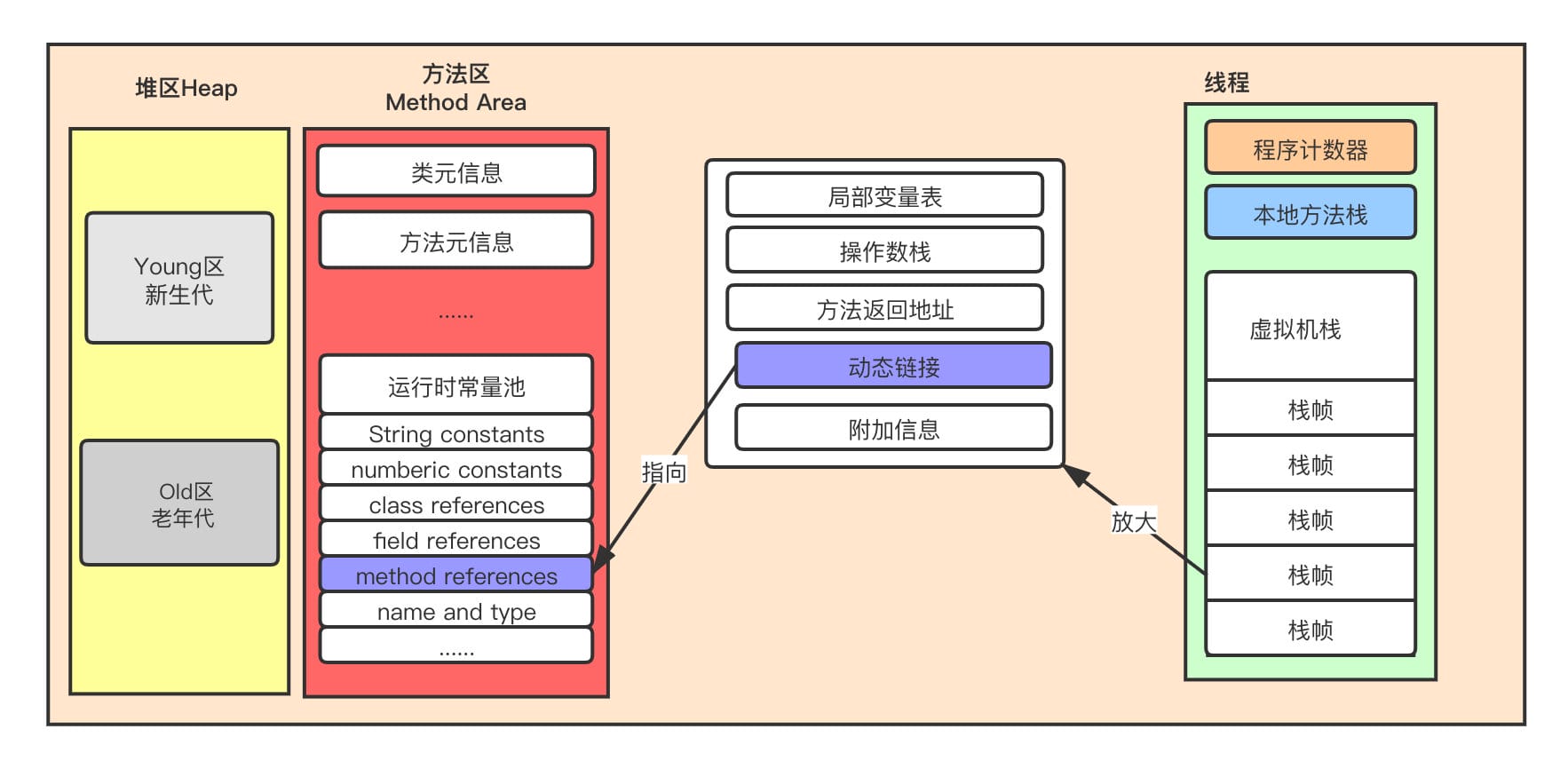
堆
创建的对象存在于堆中
栈上的局部变量表,可以存放堆上的对象的引用,静态变量也可以存放堆对象的引用,线程共享
堆溢出 OutOfMemory,-Xmx(max 最大值) -Xms(初始 total)
方法区
- 类的基本信息:InstanceKlass,加载阶段完成
- 运行时常量池(Runtime Constant Pool)是方法区的一部分。Class 文件中除了有类的版本/字段/方法/接口等描述信息外,还有一项信息是常量池(Constant Pool Table),用于存放编译期生成的各种字面量和符号引用,这部分内容将类在加载后进入方法区的运行时常量池中存放。运行期间也可能将新的常量放入池中,这种特性被开发人员利用得比较多的是
String.intern()方法。受方法区内存的限制,当常量池无法再申请到内存时会抛出OutOfMemoryError异常。 - JDK7-永久代(堆中,-XX: MaxPermSize =?),JDK8-元空间(操作系统直接内存,-XX: MaxMetaspaceSize =?)
垃圾回收
方法区的回收
类可以被回收,需要满足三个条件:
此类所有实例对象都已经被回收,在堆中不存在任何该类的实例对象以及子类对象。
加载该类的类加载器已经被回收
该类对应的 java.lang.Class 对象没有在任何地方被引用
URLClassLoader loader = new URLClassLoader(new URL[]{new URL("file:D:\\lib\\")});
Class<?> clazz = loader.loadclass("com.itheima.my.A");
Object o = clazz.newInstance();引用计数法
- 为每个对象维护一个引用计数器,引用时加 1,取消引用时减 1
- 循环引用会导致无法回收
可达性分析法
- 将对象分为两类:垃圾回收的根对象(GC Root) 和 普通对象
- 如果从某个对象到某个 GC Root 可达,则不可回收
GC Root 对象:
- 线程 Thread 对象,引用线程栈帧中的方法参数,局部变量
- 系统类加载器加载的 java.lang.Class 对象,引用类中的静态变量
- 监视器对象,用来保存同步锁 synchronized 关键词持有的对象
- 本地方法调用时使用的全局对象
五种对象引用
- 强引用:到 GC Root 可达
- 软引用:常用于缓存中,SoftReference 引用的对象,当内存不足会回收

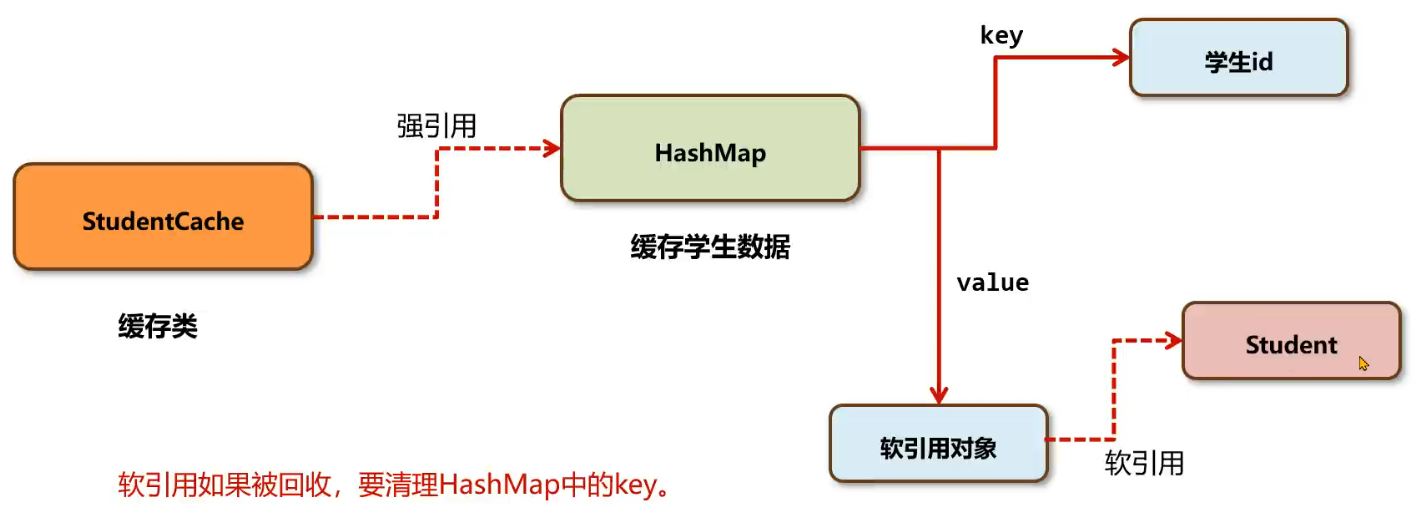
- 弱引用:在垃圾回收时,不管内存够不够都会回收,主要用于 ThreadLocal,WeekReference
- 虚引用:不能通过虚引用对象获取到包含的对象,唯一用途是当对象被垃圾回收时可以接收到对应的通知,直接内存回收
- 终结器引用:在对象需要被回收时,终结器引用会关联对象并放置在 Finalizer 类的引用队列中,执行 finalize 方法后二次回收
垃圾回收算法
垃圾回收通过单独的 GC 线程完成,会有部分阶段需要停止所有的用户线程,这个过程被称之为 STW(Stop The World)
-verbose: gc 打印垃圾回收日志
标记 - 清除算法
- 标记阶段:将所有存活的对象进行标记,Java 使用可达性分析算法,从 GC Root 通过引用链遍历出所有存活对象
- 清除阶段:从内存中删除没有被标记的对象
缺点:碎片化,分配速度慢(需要维护空闲链表指向碎片空间)
复制算法
- 准备两块对象 From 和 To 空间,对象分配阶段,创建对象到 From 空间
- GC 阶段开始,将 GC Root 及其关联对象搬运到 To 空间
- 清理 From 空间,并将名称互换
优点:吞吐量高,但不如标记清除算法,不会发生碎片化
缺点:内存效率低,只有一半
标记 - 整理算法
标记压缩算法,对内存碎片化进行优化:
- 标记阶段:将所有存活对象进行标记
- 整理阶段:将存活对象移动到内存的一端,清理掉非存活对象的空间
优点:内存使用效率高,不会发生碎片化
缺点:整理效率低
分代算法
组合使用上面算法,将整个内存划分为年轻代(Eden, s0, s1)和老年代
新生代使用: 复制算法
老年代使用: 标记 - 清除 或者 标记 - 整理 算法
创建对象,首先放入 Eden 区,当 Eden 区满时,触发 Minor GC
Minor GC 将 Eden 和 From 区需要回收的对象回收,没有回收的放入 To 区,并名称互换
每次 Minor GC 会将对象的年龄 +1,初始为 0,当达到阈值(最大 15)时,会将对象放入老年代
当老年代区满时,触发 Full GC
如果 Minor GC 和 Full GC 都无法回收空间,且需要放入新对象,会 OutOfMemory,两个都会 STW
垃圾回收器
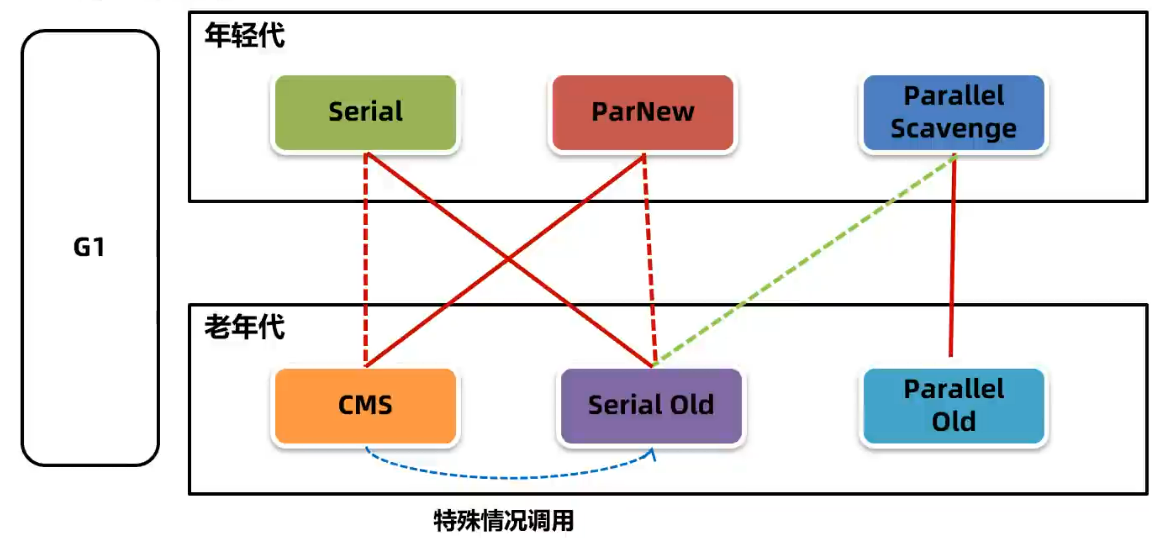
年轻代-Serial / 老年代-SerialOld 垃圾回收器
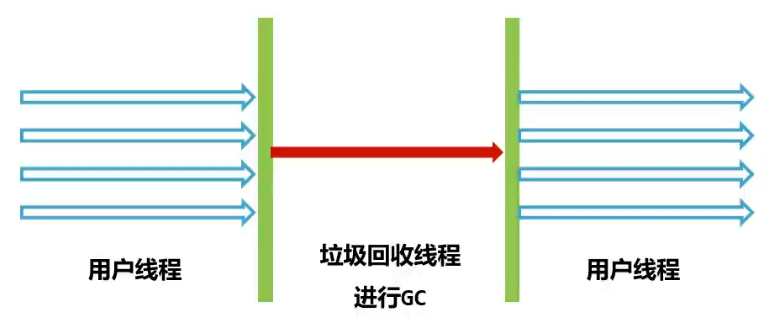
-XX:+UseSerialGC,新生代,老年代都使用串行回收器
一种 单线程串行回收年轻代 的垃圾回收器,复制算法
优点:单 CPU 处理器吞吐量出色
缺点:多 CPU 吞吐量不如其他垃圾回收器,堆偏大会导致 STW 时间过长
年轻代-ParNew
ParNew 使用 多线程进行垃圾回收
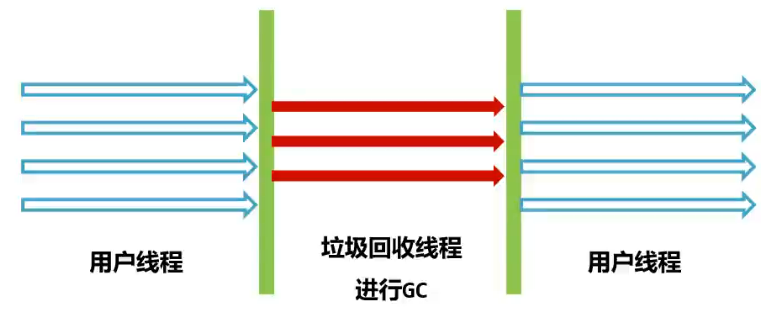
- 优点:多 CPU 处理器停顿时间短
- 缺点:吞吐量和停顿时间不如 G1 回收器
-XX:+UserParNewGC 新生代使用 ParNew 回收器,老年代使用串行回收器
老年代-CMS 垃圾回收器
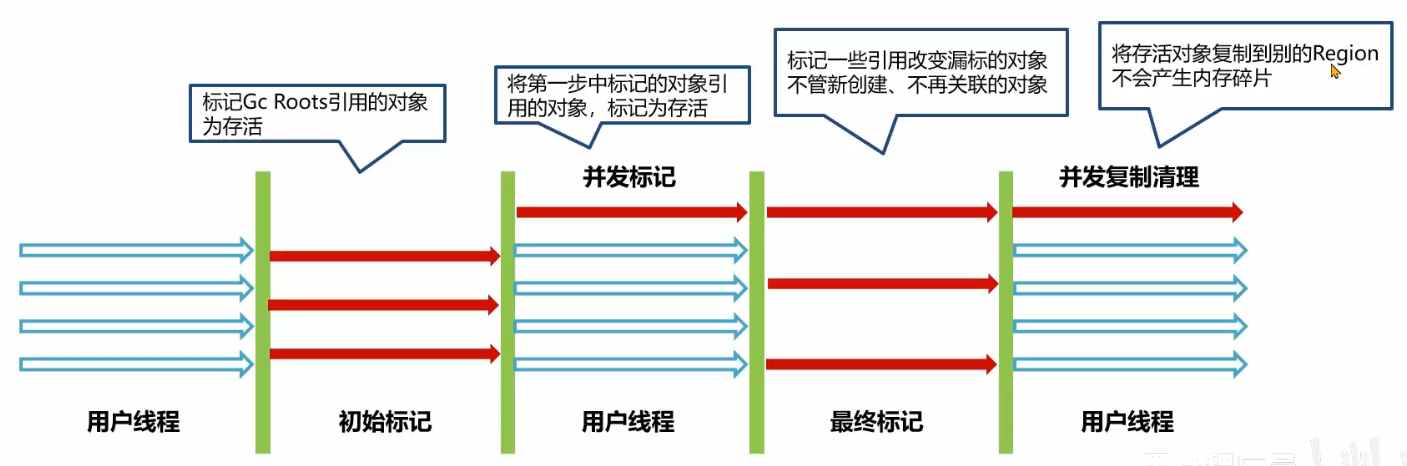
CMS 关注系统的暂停时间,允许用户线程和回收线程同时执行,标记-清除算法,内存碎片会在 Full GC 处理,会导致用户现场的暂停
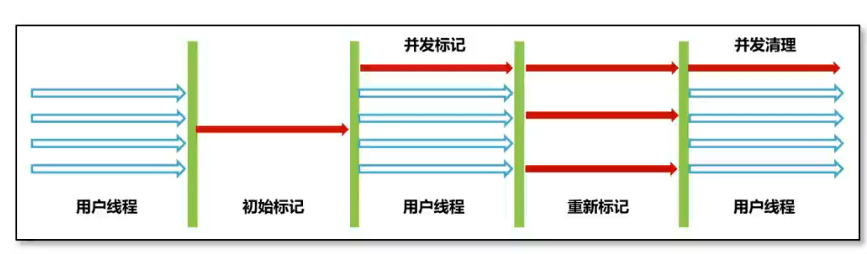
- 初始标记:标记 GC Root 直接关联的对象
- 并发标记:标记所有的对象,并发
- 重新标记:标记并发标记中的对象
- 并发清理:清理未标记的对象
- 优点:同时执行,用户体验好
- 缺点:内存碎片,浮动垃圾(并发时产生的垃圾)
- 如果老年代内存不足分配对象,CMS 会退化成 Serial Old 回收老年代
-XX:+UseConcMarkSweepGC 新生代使用 ParNew,老年代使用 CMS
年轻代-PS / 老年代-PO
Parallel Scavenge 是 JDK8 默认的年轻代垃圾回收器,多线程并行回收,关注的是系统的吞吐量。具备 自动调整堆内存大小 的特点。复制算法
- 优点:吞吐量高,手动可控,动态调整堆的参数
- 缺点:STW
Parallel Old 老年代多线程并发收集,标记整理算法
- 优点:多核并发高
- 缺点:STW
-XX: UseParallelGC 或 -XX: UseParallelOldGC 使用 PS/PO 组合
-XX: MaxGCPauseMillis = n,设置最大停顿时间,
-XX: GCTimeRatio = n,设置吞吐量为 n(用户线程执行时间 = n/n + 1)
-XX: UseAdaptiveSizePolicy,设置自动调整堆大小
G1 垃圾回收器
JDK9 后默认垃圾回收器
支持巨大的堆空间回收,并有较高的吞吐量
支持多 CPU 并行垃圾回收
允许用户设置最大暂停时间
G1 的整个堆会被划分成多个大小相等的区域,称之为区 Region,区域不要求是连续的。分为 Eden、Survivor、Old 区。Region 的大小通过堆空间大小/2048 计算得到,也可以通过参数-XX: G1HeapRegionSize = 32m 指定(其中 32m 指定 region 大小为 32M),Region size 必须是 2 的指数幂,取值范围从 1M 到 32M。
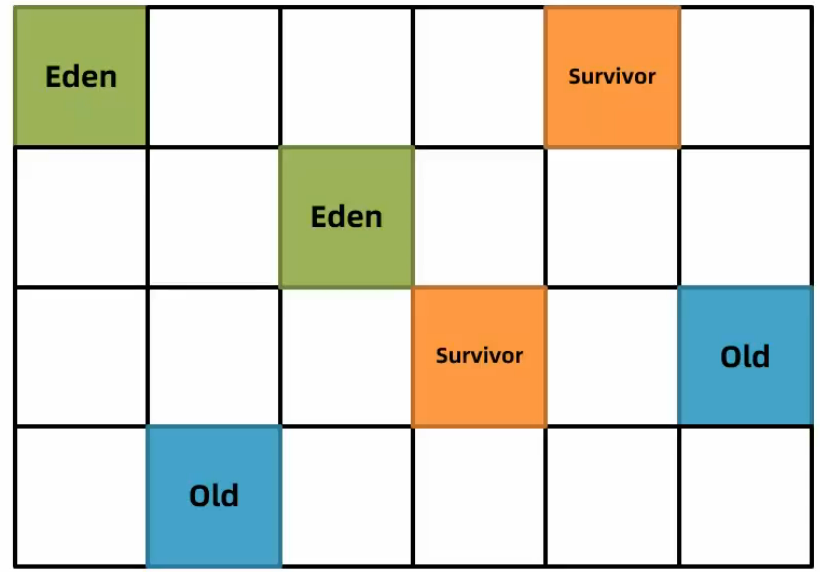
年轻代回收(Young GC):回收 Eden 区和 Survivor 区中不用的对象。 会导致 STW,G1 中可以通过参数-XX: MaxGCPauseMillis = n(默认 200)设置每次垃圾回收时的最大暂停时间毫秒数,G1 垃圾回收器会尽可能地保证暂停时间。
- 新创建的对象会存放在 Eden 区。当 G1 判断年轻代区不足(max 默认 60%),无法分配对象时需要回收时会执行 Young GC.
- 标记出 Eden 和 Survivor 区域中的存活对象
- 根据配置的最大暂停时间选择某些区域 将存活对象复制到一个新的 Survivor 区中(年龄+1),清空这些区域。
- G1 在进行 YoungGC 的过程中会去记录每次垃圾回收时每个 Eden 区和 Survivor 区的平均耗时,以作为下次回收时的参考依据。这样就可以 根据配置的最大暂停时间计算出本次回收时最多能回收多少个 Region 区域 了。比如-XX: MaxGCPauseMillis = n(默认 200),每个 Region 回收耗时 40ms,那么这次回收最多只能回收 4 个 Region。
- 后续 YoungGC 时与之前相同,只不过 Survivor 区中存活对象会被搬运到另一个 Survivor 区。
- 当某个 存活对象的年龄到达阈值(默认 15),将被放入老年代。
- 部分对象如果大小超过 Region 的一半,会直接放入老年代,这类老年代被称为 Humongous 区。比如堆内存是 4G,每个 Region 是 2M,只要一个大对象超过了 1M 就被放入 Humongous 区,如果对象过大会横跨多个 Region。
- 多次回收之后,会出现很多 Old 老年代区,此时总堆占有率达到阈值时(-XX: InitiatingHeap0ccupancyPercent 默认 45%)会触发 混合回收 MixedGC。回收所有年轻代和部分老年代的对象以及大对象区。采用复制算法来完成。
混合回收(MixedGC):
混合回收分为:初始标记(initial mark)、并发标记(concurrent mark)、最终标记(remark 或者 FinalizeMarking)、并发清理(cleanup) 复制算法
G1 对 老年代的清理 会 选择存活度最低的区域来进行回收,这样可以保证回收效率最高,这也是 G1(Garbagefirst)名称的由来。
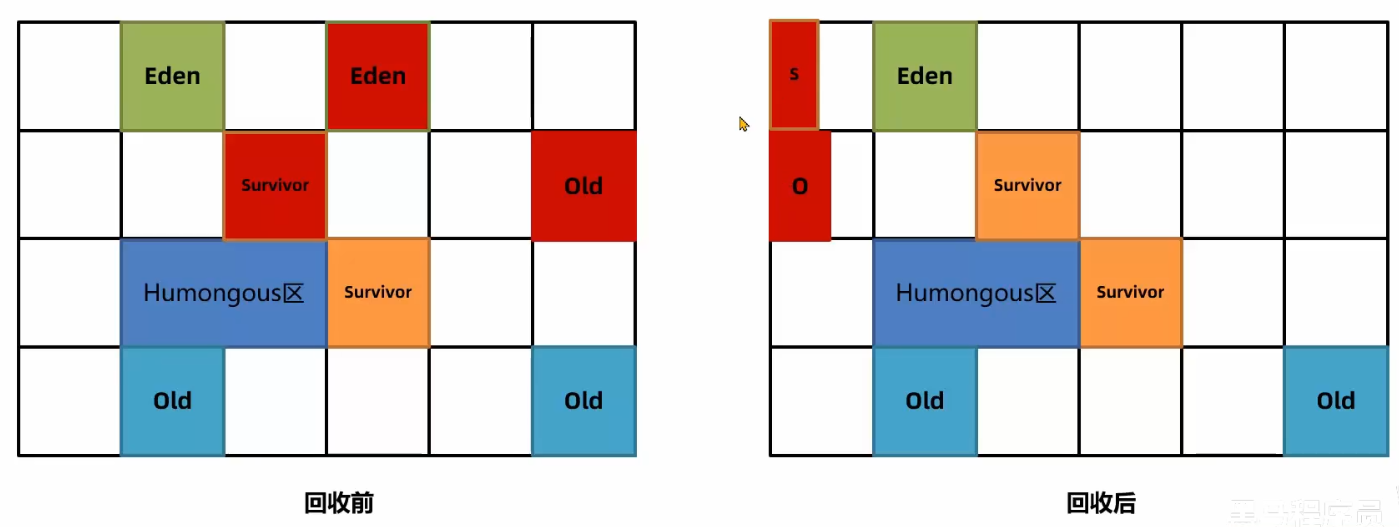
如果清理过程中发现没有足够的空 Region 存放转移的对象,会出现 FullGC。单线程执行标记-整理算法,此时会导致用户线程的暂停。所以尽量保证应该用的堆内存有一定多余的空间。
-XX:+UseG1GC,打开 G1 -XX: MaxGCPauseMills,最大暂停时间
优点:对比较大的堆如超过 6G 的堆回收时,延迟可控,不会产生垃圾碎片,并发标记的 SATB 算法效率高
实战
基础概念
内存泄漏:在 Java 中如果不再使用一个对象,但是该对象仍在 GC ROOT 的引用链上,这个对象就不会被垃圾回收器回收
内存溢出:是指程序在申请内存时,没有足够的内存空间供其使用,出现 out of memory
排查问题
- top 命令:查看内存信息 RES(常驻内存),SHA(共享内存),MEM(内存占用),默认按 CPU 排序,按下 M 后按 MEM 排序
- jvisualvm:java 自带可视化
- Arthas:tunnel 隧道服务管理所有需要监控的程序
内存泄漏原因
- 不正确的 equals()和 hashCode():Map 同一对象映射到不同地方,导致存在多个对象无法垃圾回收
- 内部类引用外部类
- ThreadLocal 的使用:使用创建线程不会内存泄漏,使用线程池不 remove 会内存泄漏
- String 的 intern 方法:JDK6 中字符串常量池放在永久代中,JDK放在堆中,保存大量字符串并被引用无法回收会内存溢出
- 通过静态字段保存对象
- 资源没有正常关闭