Redis 源码
String SDS
特性
- String 是最基本的 Redis 数据类型;
- String 是二进制安全,存入和获取的数据相同;
- Redis 字符串存储字节序列,包括文本、序列化对象和二进制数组;
- String 存储的 value 值最大为 512MB;
存储结构
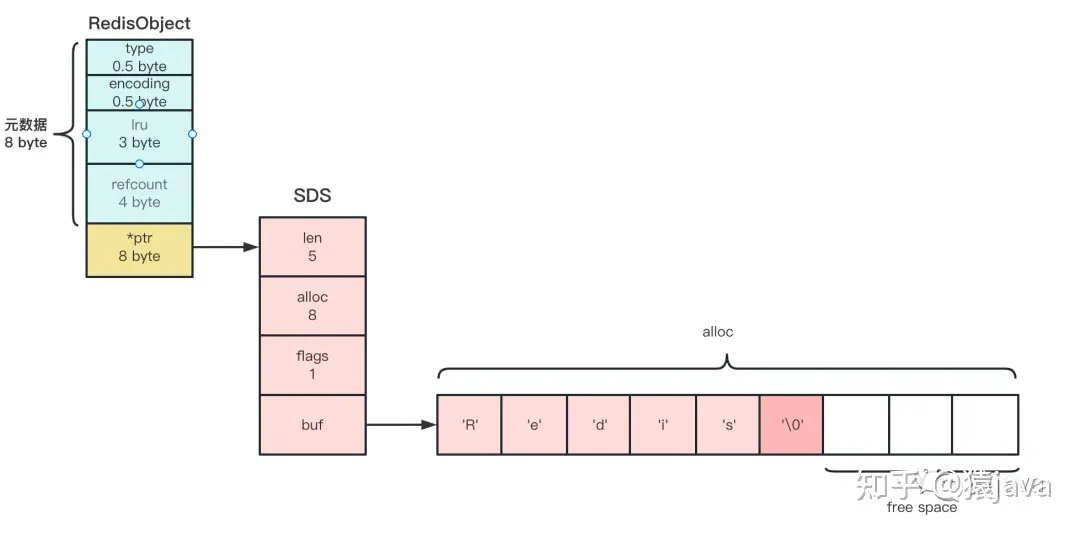
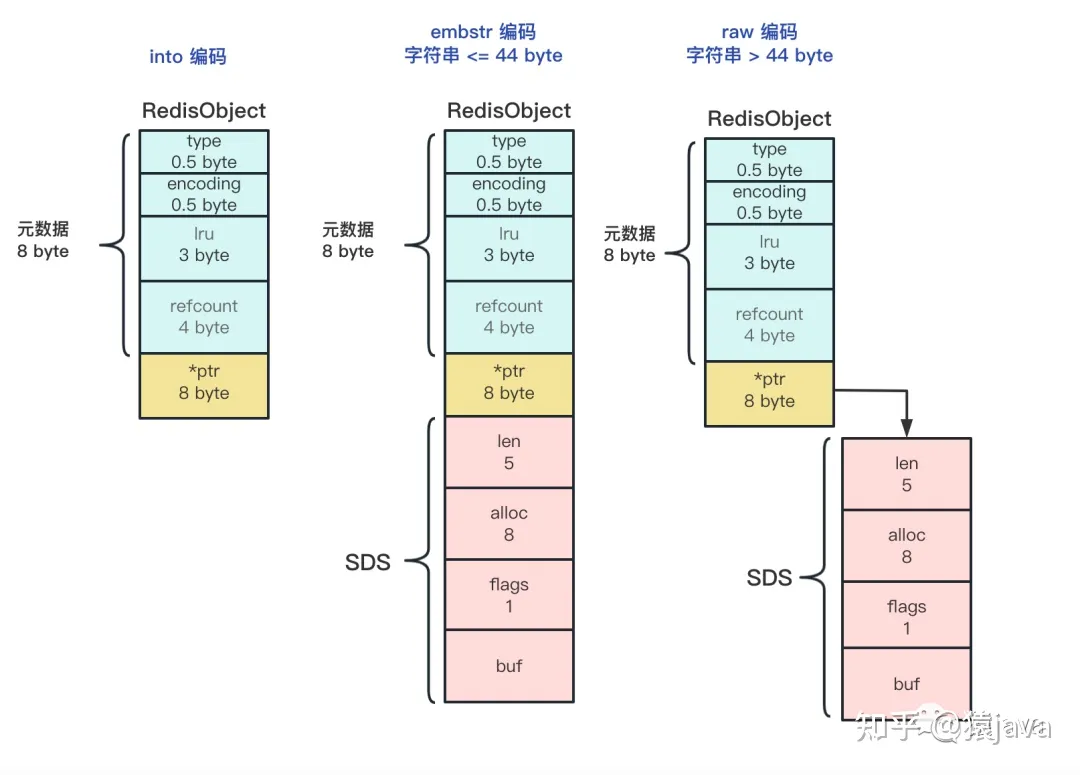
SDS 各个属性说明:
- len:表示 buf 已用空间的长度,占 4 个字节,不包括 '\0';
- alloc:表示 buf 的实际分配长度,占 4 个字节,不包括 '\0';
- flags:标记当前字节数组是 sdshdr8/16/32/64 中的哪一种,占 1 个字节;
- buf:表示字节数组,保存实际数据。为了表示字节数组的结束,Redis 会自动在数组最后加一个'\0',需要额外占用 1 个字节的开销
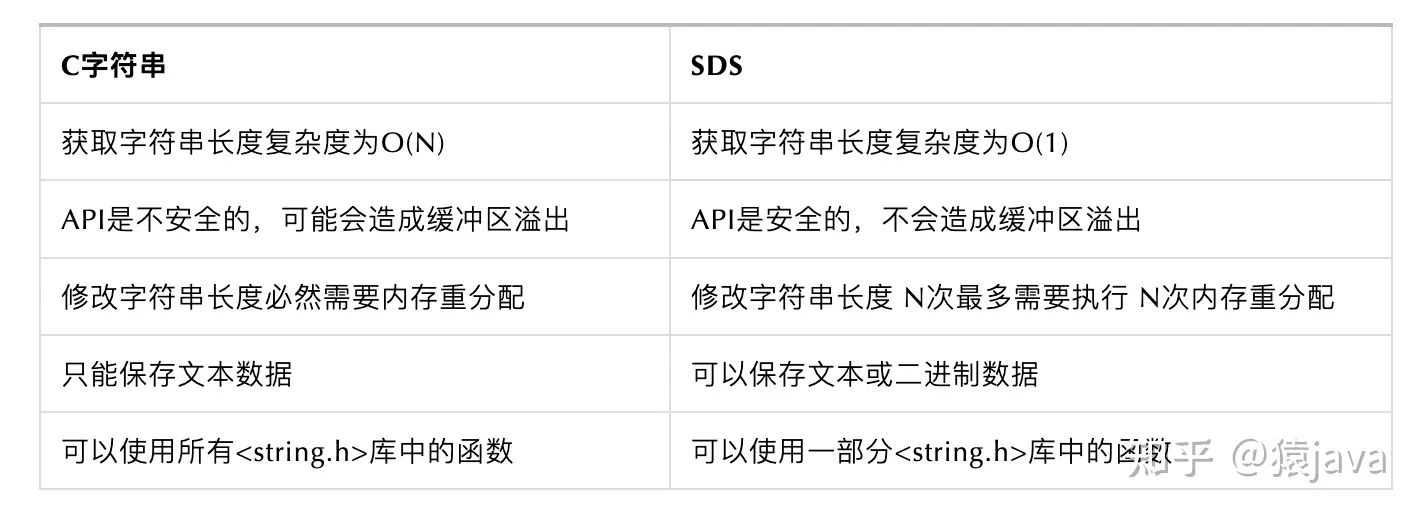
SDS vs cstring
可以避免缓冲区溢出:C 语言中的字符串被修改(比如拼接)时,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。SDS 被修改时,会先根据 len 属性检查空间大小是否满足要求,如果不满足,则先扩展至所需大小再进行修改操作。
获取字符串长度的复杂度较低:C 语言中的字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O(n)。SDS 的长度获取直接读取 len 属性即可,时间复杂度为 O(1)。
减少内存分配次数:为了避免修改(增加/减少)字符串时,每次都需要重新分配内存(C 语言的字符串是这样的),SDS 实现了空间预分配和惰性空间释放两种优化策略。当 SDS 需要增加字符串时,Redis 会为 SDS 分配好内存,并且根据特定的算法分配多余的内存,这样可以减少连续执行字符串增长操作所需的内存重分配次数。当 SDS 需要减少字符串时,这部分内存不会立即被回收,会被记录下来,等待后续使用(支持手动释放,有对应的 API)。
二进制安全:C 语言中的字符串以空字符
\0作为字符串结束的标识,这存在一些问题,像一些二进制文件(比如图片、视频、音频)就可能包括空字符,C 字符串无法正确保存。SDS 使用 len 属性判断字符串是否结束,不存在这个问题。
Zset
Set 有两种不同的实现,分别是 ziplist(压缩列表) 和 skiplist(跳表),具体使用哪种结构进行存储的规则如下:
- 当有序集合对象同时满足以下两个条件时,使用 ziplist:
- ZSet 保存的键值对数量少于 128 个;
- 每个元素的长度小于 64 字节。
- 如果不满足上述两个条件,那么使用 skiplist
压缩列表

跳表
有序链表在添加、查询、删除的平均时间复杂都都是 O(n)即线性增长,所以一旦节点数量达到一定体量后其性能表现就会非常差劲。而跳表我们完全可以理解为在原始链表基础上,建立多级索引,通过多级索引检索定位将增删改查的时间复杂度变为 O(log n)。

理想情况是每一层索引是下一层元素个数的二分之一, k 层索引的元素个数 r 计算公式为: r = n/2^k
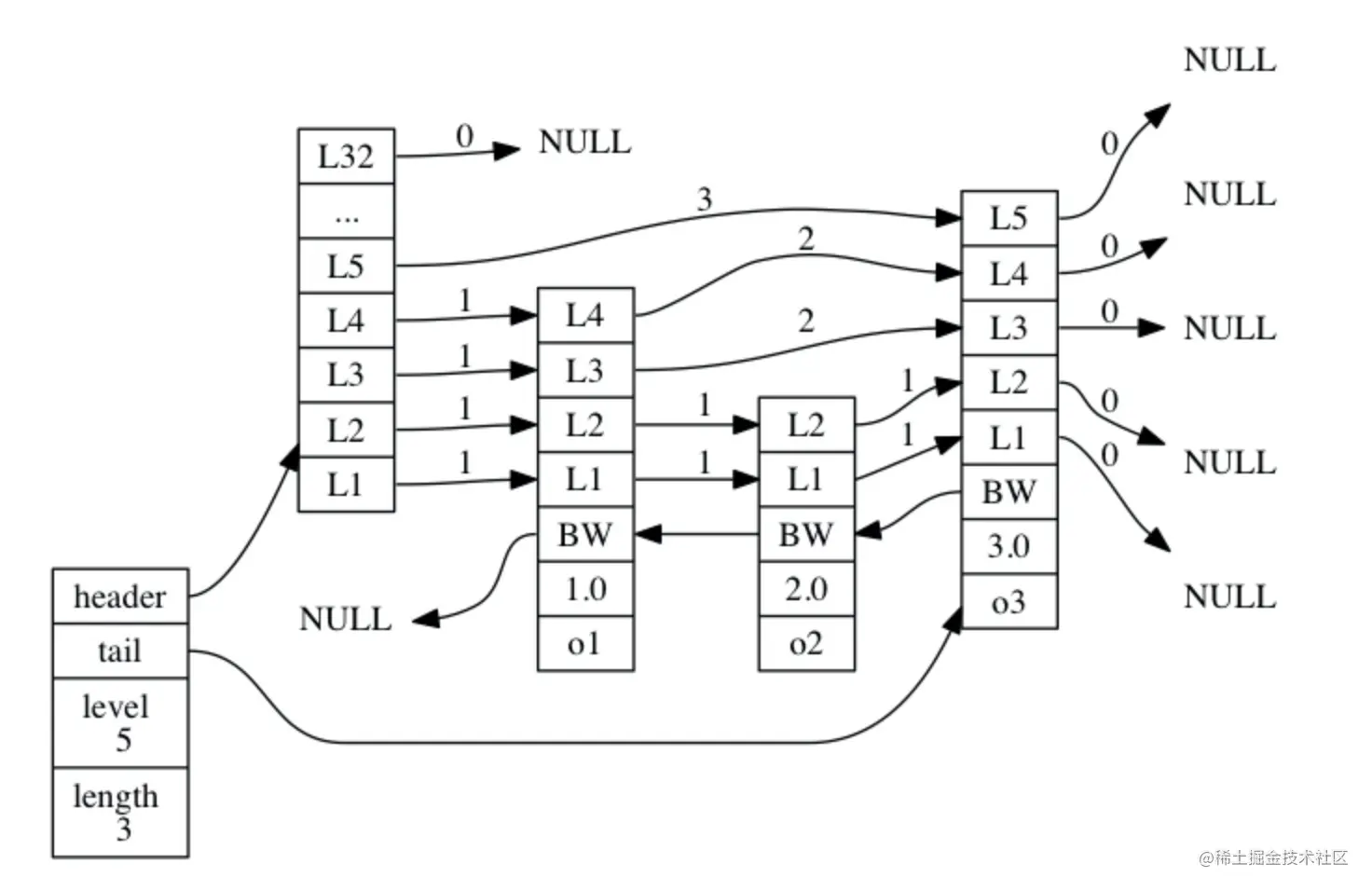
上图展示了一个跳跃表示例,位于图片最左边的示 zskiplist 结构,该结构包含以下属性:
header:指向跳跃表的表头节点。tail:指向跳跃表的表尾节点。level:记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内)。length:记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内)。
位于 zskiplist 结构右方的是四个 zskiplistNode 结构, 该结构包含以下属性:
- 层(level):节点中用
L1、L2、L3等字样标记节点的各个层,L1代表第一层,L2代表第二层,以此类推。每个层都带有两个属性:前进指针和跨度。前进指针用于访问位于表尾方向的其他节点,而跨度则记录了前进指针所指向节点和当前节点的距离。在上面的图片中,连线上带有数字的箭头就代表前进指针,而那个数字就是跨度。当程序从表头向表尾进行遍历时,访问会沿着层的前进指针进行。 - 后退(backward)指针:节点中用
BW字样标记节点的后退指针,它指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。 - 分值(score):各个节点中的
1.0、2.0和3.0是节点所保存的分值。在跳跃表中,节点按各自所保存的分值从小到大排列。 - 成员对象(obj):各个节点中的
o1、o2和o3是节点所保存的成员对象。
注意:表头节点和其他节点的构造是一样的: 表头节点也有后退指针、分值和成员对象, 不过表头节点的这些属性都不会被用到, 所以图中省略了这些部分, 只显示了表头节点的各个层。
跳表 vs 平衡树
先来说说它和平衡树的比较,平衡树我们又会称之为 AVL 树,是一个严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差不超过 1,即平衡因子为范围为 [-1,1])。平衡树的插入、删除和查询的时间复杂度和跳表一样都是 O(log n)。
对于范围查询来说,它也可以通过中序遍历的方式达到和跳表一样的效果。但是它的每一次插入或者删除操作都需要保证整颗树左右节点的绝对平衡,只要不平衡就要通过旋转操作来保持平衡,这个过程是比较耗时的。
跳表 vs 红黑树
红黑树(Red Black Tree)也是一种自平衡二叉查找树,它的查询性能略微逊色于 AVL 树,但插入和删除效率更高。红黑树的插入、删除和查询的时间复杂度和跳表一样都是 O(log n)。
红黑树是一个 黑平衡树,即从任意节点到另外一个叶子叶子节点,它所经过的黑节点是一样的。当对它进行插入操作时,需要通过旋转和染色(红黑变换)来保证黑平衡。不过,相较于 AVL 树为了维持平衡的开销要小一些。
相比较于红黑树来说,跳表的实现也更简单一些。并且,按照区间来查找数据这个操作,红黑树的效率没有跳表高。
跳表 vs B+树
所以,B+树更适合作为数据库和文件系统中常用的索引结构之一,它的核心思想是通过可能少的 IO 定位到尽可能多的索引来获得查询数据。对于 Redis 这种内存数据库来说,它对这些并不感冒,因为 Redis 作为内存数据库它不可能存储大量的数据,所以对于索引不需要通过 B+树这种方式进行维护,只需按照概率进行随机维护即可,节约内存。而且使用跳表实现 zset 时相较前者来说更简单一些,在进行插入时只需通过索引将数据插入到链表中合适的位置再随机维护一定高度的索引即可,也不需要像 B+树那样插入时发现失衡时还需要对节点分裂与合并